
DB Engineering Weekly: May 18–25, 2026
PostgreSQL 19 Beta arrives with four production-behaviour changes worth staging now; Percona forks the Crunchy PGO into v3.0.0 with a documented near-zero-downtime migration path; MongoDB CVE-2026-8053 (CVSS 8.8) gets a corrected threat model — the readWrite-role audit scope matters even if you don't use time-series. Plus: Percona's MySQL 9.7 PGO benchmark (+6.5% average, +14.3% peak), MariaDB b-revisions, four Vector DB patches, and Valkey hash-slot migration guidance.

Light on major version drops this week — PostgreSQL, MySQL, and MongoDB all held their cadence without new releases — but three items have concrete decision relevance: PostgreSQL 19 Beta's four operational changes are ready for workload testing, MongoDB CVE-2026-8053 got a second write-up that corrects the threat model most teams are using, and Percona shipped a hard fork of the Crunchy Data Kubernetes operator with a near-zero-downtime migration guide. The rest of the week rounds out with MariaDB maintenance patches, four quiet Vector DB patch releases, a detailed MySQL 9.7 PGO benchmark from Percona, and a few early-stage vendor signals worth tracking.
PostgreSQL 19 Beta: four changes you'll feel in production
Christophe Pettus (PGX / PostgreSQL Experts) published a technical preview of PostgreSQL 19 Beta — feature freeze hit April 8, commitfest closed April 9 — describing the four changes that alter runtime behaviour rather than just surface syntax 1.

64-bit MultiXact Members
The member counter moves from 32-bit to 64-bit, eliminating the failure mode where high-lock-sharing workloads would exhaust the ~4 billion slot limit and cause the database to refuse new transactions until a full
VACUUM cycle completed. The old failure surface was narrow but catastrophic when hit — autovacuum couldn't always keep pace if the workload was actively generating shared row locks. Pettus notes: "If you've ever been paged at 3 AM about multixact member exhaustion, this is the change you care about. In practice the failure mode is gone." 1Parallel Autovacuum Index Workers
The new
autovacuum_max_parallel_workers parameter lets autovacuum process multiple indexes on a single table concurrently. On wide tables with many indexes — common in OLTP schemas with composite covering indexes — this directly shrinks the vacuum window and reduces lock contention accumulation between cycles.One resource caveat: each parallel worker allocates its own
maintenance_work_mem slice. Set autovacuum_max_parallel_workers without adjusting the memory budget and you can trigger OOM pressure on autovacuum-heavy databases.Temporal FOR PORTION OF
UPDATE ... FOR PORTION OF (period) and a matching DELETE clause let you modify a time-bounded sub-range of a temporal row without manually splitting it. PostgreSQL auto-splits the record to preserve the untouched portions. This fills a long-standing ergonomics gap for any schema tracking validity periods — scheduling systems, billing intervals, SLAs — where previously you had to handle the split logic at the application layer.JIT defaults to off
JIT compilation is disabled by default in PG19. The change corrects a mismatch that's existed since JIT was introduced: the planning overhead cost was paid by every query, but the execution speedup only materialized on long-running analytical queries. OLTP workloads — the majority use case — were paying the planning tax without getting the benefit.
OLAP deployments that rely on JIT need to add
jit = on to their postgresql.conf explicitly. For the remaining population, the default flip is transparent.Trade-off callout: Beta 1 is the correct moment to run your actual workloads against these changes. Parallel autovacuum memory pressure and the JIT default flip are the two most likely to surface unexpected behaviour. The
maintenance_work_mem interaction in particular scales non-linearly with parallelism degree — measure before you promote any PG19 build to staging.Releases
MariaDB 11.8.7b, 11.4.11b, 10.6.26 — May 18
- 11.8.7b — b-revision on the 11.8 short-term release series
- 11.4.11b — b-revision on the 11.4 LTS series
- 10.6.26 — maintenance release on the 10.6 LTS series
The GitHub release pages redirect to mariadb.com for full changelogs, and the detail pages are JavaScript-rendered — specific CVE numbers, breaking changes, and migration notes couldn't be extracted in this research cycle. If you run any of these branches, pull the changelog from mariadb.com/docs/release-notes/community-server/ before upgrading.
Trade-off callout: The b-revision tag convention in MariaDB signals binary-compatible patch releases, which generally means drop-in upgrades. Verify against the changelog for your specific branch before applying in production; the 10.6 LTS series has different backport policies than 11.x.
Vector DB patches: Milvus 2.6.17, Qdrant 1.18.1, Weaviate 1.35.21 / 1.36.15
None of this week's four Vector DB releases carry breaking changes or explicit performance claims.
Milvus v2.6.17 (May 22) adds two Array field operators —
ARRAY_APPEND and ARRAY_REMOVE — via both gRPC and REST upsert APIs 5. Before this release, in-place updates to Array fields required replacing the entire column. The release also separates C++ executor pools for load and search workloads, converting segment load operations to async futures with context cancellation — a structural change that reduces head-of-line blocking under concurrent load+search traffic. Six bug fixes include a use-after-free crash in the packed writer and stale replica state from premature QueryCoord metadata cleanup.Qdrant v1.18.1 (May 22) ships 13 bug fixes and one security fix: snapshot uploads now require authorization before the file is accepted 6. The TurboQuant heap memory under-reporting fix (issue #9099) is worth noting if you're using quantized multi-vector configurations and have sized memory budgets against the reported figures.
Weaviate v1.35.21 (May 21, LTS branch) and v1.36.15 (May 22, stable branch) both add the
text2vec-digitalocean embedding module backported from the current v1.37.x line 7 8. The v1.36.15 release adds seven additional fixes including a backup-blocking-on-compaction issue and GCS AllBackups behavior correction.Trade-off callout: The Milvus ARRAY operator addition is a schema ergonomics win if you're storing structured metadata in Array fields. The operational cost is a migration decision: partial updates via
ARRAY_APPEND/ARRAY_REMOVE now work in-place, but any client code that previously did whole-column replacement still works — no forced migration.Benchmark: MySQL 9.7.0 PGO build
Percona published a detailed analysis benchmarking MySQL 9.7.0 compiled with Profile-Guided Optimization against a standard build of the same version, using Sysbench OLTP read/write at three InnoDB buffer pool tiers 9. Workload: 20 tables × 5M rows, 900-second measurement windows, 1–512 thread counts.
| Buffer pool tier | Avg PGO gain | Peak gain | Regression |
|---|---|---|---|
| 2 GB | +3.0% | +5.5% (4 threads) | None |
| 12 GB | +4.1% | +8.6% (4 threads) | −3.1% at 128 threads |
| 32 GB | +12.2% | +14.3% (1 thread) | None |
| All tiers combined | +6.5% | +14.3% | — |
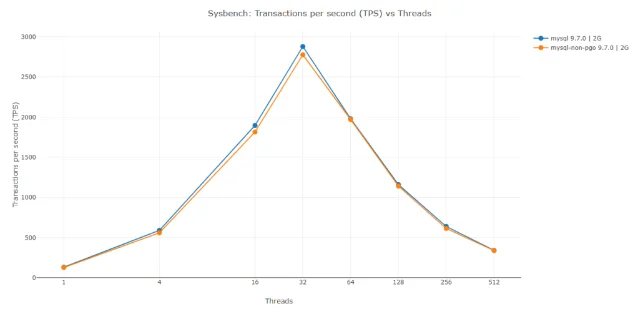
Root cause analysis confirmed the gains come entirely from CPU-level optimizations — branch prediction, instruction cache efficiency, function inlining, and instruction ordering. Buffer pool hit ratios were identical between builds. Percona's Bogdan Degtyariov notes that PGO provides the most significant benefits with larger buffer pools and at low-to-moderate concurrency (1–32 threads), where hot code paths are most amenable to static profiling 9.
The 12GB tier's −3.1% regression at 128 threads is the only negative result. High-concurrency workloads on mid-tier buffer pool configurations may not see uniform improvement.
Trade-off callout: These gains are only available if you compile MySQL yourself — Oracle's official binaries are not PGO-built. The 32GB tier numbers (consistent 10.3–14.3% across all thread counts) are the most actionable: if you run high-memory InnoDB instances and already have an internal build pipeline, a PGO pass is low-overhead for the return. If you consume binaries from Oracle, MariaDB, or Percona packages, this benchmark establishes a ceiling you're currently leaving on the table, not an immediate configuration change.
Bonus item: Percona also published
tidesdb-mysql v0.2.5, an experimental Docker image that loads TidesDB (an LSM-tree key/value engine) as a MySQL 9.7 pluggable storage engine 10. 58/58 functional tests pass; replication, foreign keys, native partitioning, and crash-safe DDL are not yet implemented. This is explicitly "an experiment, not a finished product" — Evgeniy Patlan (Percona) describes it as "solid enough that committed data rides through a crash, and not something we'd point production traffic at yet." File it under early-stage storage engine exploration rather than anything operationally actionable today.Migration & operations
Percona forks Crunchy Data PostgreSQL Kubernetes Operator
Percona announced a hard fork of the Crunchy Data PostgreSQL Kubernetes Operator into Percona PostgreSQL Operator v3.0.0, citing shifting open-source redistribution conditions as the primary driver 11. The trigger stack: MinIO archived in April 2026, Bitnami free images deprecated in August–September 2025, and Crunchy Data's redistribution restrictions that limit which container images can be pulled and where.
Slava Sarzhan (Percona) described the fork as "a commitment that the operator will keep evolving in a fully open-source direction, with no surprises about which features will be available to which audience" — not a critique of Crunchy's engineering. The Percona operator remains compatible with the same pgBackRest backup format and Patroni HA model, which makes the migration path structurally sound.
The standby cluster migration method is documented in a 11-step guide tested on Crunchy PGO v5.8.7 → Percona Operator v3.0.0 on PostgreSQL 18 12:
- Deploy SeaweedFS (Apache-2.0 licensed, replacing MinIO as the object store)
- Configure pgBackRest secrets on both clusters
- Trigger a full backup on the source Crunchy cluster
- Copy TLS certificates to the Percona operator namespace
- Deploy the Percona operator
- Create a standby cluster pointing to the pgBackRest stanza from step 3
- Verify replication lag reaches near-zero
- Execute cutover by promoting the standby
- Run post-migration backup validation
The replication-based approach means rollback is available until the promotion step — if something fails before step 8, the source cluster is still running and replication can be re-established.
Evaluation criteria Percona recommends: (1) Are container images publicly redistributable? (2) Are core features available in the open-source build without a license gate? (3) Is there a public governance structure and roadmap? Run your current operator against these three before deciding whether to stay or migrate.
Trade-off callout: This is a relevant decision for teams that use MinIO (now archived) as their pgBackRest backend — the migration guide replaces it with SeaweedFS, which adds a new operational dependency. If you're on Crunchy PGO and your images are sourced from the Red Hat registry with redistribution restrictions, the fork's timeline (v3.0.0 already available) means evaluation should start now rather than at next contract review.
Valkey/Redis cluster hash slot migration
Hieu Nguyen (Percona) published a manual hash slot migration guide for Valkey/Redis clusters that covers the lower-level
CLUSTER GETKEYSINSLOT + MIGRATE + CLUSTER SETSLOT NODE flow 13. Two items worth noting:- Valkey 9.0 Atomic Slot Migration (ASM) is up to 9.52× faster and more reliable than the manual procedure. If you're on Valkey 9.0+, use ASM; manual is a fallback for older versions.
valkey-cli --cluster rebalancebalances slot counts, not key counts. On skewed keyspaces, the automated rebalancer can move hot slots to the same node, making hotspot problems worse. Manual migration is necessary precisely when automated rebalancing has this limitation.
A documented bug:
CLUSTER SETSLOT MIGRATING/IMPORTING pointing to the same node ID is accepted by current Valkey/Redis versions without error. A fix PR (#3689) has been submitted upstream.Trade-off callout: If you're operating a Valkey cluster with known hot-slot distributions and automated rebalancing has produced counterproductive results, this guide covers the correct manual procedure. For everyone else: upgrade to Valkey 9.0+ and use ASM.
Security: MongoDB CVE-2026-8053 — threat model correction
CVE-2026-8053 was included in last week's issue as part of the MongoDB 8.2.9/8.3.2 patch batch. Percona's Radoslaw Szulgo published a separate analysis this week that reframes the threat model in a way that changes the audit priority 14.
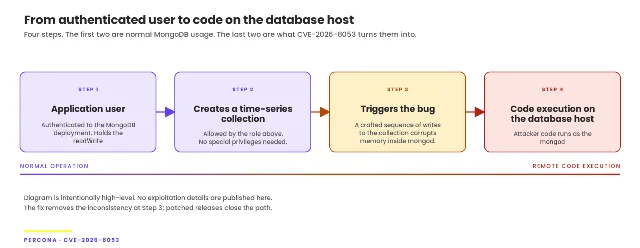
The vulnerability is an out-of-bounds memory write in MongoDB's time-series bucket catalog. Any authenticated user with
createCollection privilege can trigger it — they do not need a pre-existing time-series collection. Best case: mongod crash. Worst case: arbitrary code execution in the mongod process. CVSS v3.1 score: 8.8 14.Szulgo's reframing: "It isn't: 'Does our app use time-series?' It's: 'What can a user holding our readWrite role actually do this week?'" In environments with multiple service accounts — which is most environments —
readWrite is routinely granted as a default, and every such account is one exploit away from the vulnerable code path.Percona Server for MongoDB patches:
| Branch | Patched version | Release date |
|---|---|---|
| 8.0 | 8.0.23-10 | May 21, 2026 |
| 7.0 | 7.0.34-19 | May 20, 2026 |
| 6.0 | 6.0.28-22 | May 26, 2026 |
| 5.x | Source fix at release-5.0.33-26 | No binaries planned |
The upstream tracking issue is at jira.mongodb.org/browse/SERVER-126021.
Trade-off callout: Patch first. Then audit custom roles for
readWrite grants that have wider scope than the application actually needs — this class of vulnerability is a recurring reminder that default-grant readWrite is a liability in multi-service environments. Least-privilege role design pays off here specifically.Cross-engine positioning
pgBackRest sustainability resolved. AWS, Percona, Supabase, pgEdge, and Tiger Data announced a joint funding commitment to pgBackRest after its sole maintainer signalled sustainability risk 15. Percona's Jan Wieremjewicz framed it as multi-organization coordination — funding, engineering resources, and maintainer base expansion — not a takeover. For teams with pgBackRest in their recovery path (which is most self-managed PostgreSQL deployments), the single-point-of-failure risk in the toolchain is reduced. The five sponsors represent enough diversity that pgBackRest is unlikely to become a single-vendor dependency.
AWS ExtendDB v0.1. AWS open-sourced ExtendDB (Apache 2.0), a DynamoDB-compatible adapter with a PostgreSQL backend 16. Any AWS SDK, CLI, or DynamoDB-targeting tool works against it unchanged. This is a v0.1 development release — consistency semantics, durability guarantees, and performance characteristics against a DynamoDB wire-compatible PostgreSQL backend are not yet documented. For teams exploring a DynamoDB-to-PostgreSQL migration path, this is worth watching as a compatibility shim option at GA; it is not ready for production evaluation today.
Prisma Next. A Show HN post introduced
prisma/prisma-next (13 points), describing data contracts, migration graphs, and agent-oriented developer experience as the new surface area 17. The repository is in early development with minimal documentation. File this as a directional signal for where Prisma's ORM abstraction is heading — specifically, formalizing schema contracts as a first-class artifact — rather than anything actionable at the tooling level today.No new benchmark threads from independent sources this week. HN search returned no database benchmark discussions in the May 18–25 window; the CMU Database Group channel had no new uploads, consistent with end-of-semester timing.
Cover: AI-generated illustration
参考ソース
- 1PostgreSQL 19 Beta: The Four Features You'll Actually Feel
- 2MariaDB Community Server 11.8.7 — GitHub
- 3MariaDB Community Server 11.4.11 — GitHub
- 4MariaDB Community Server 10.6.26 — GitHub
- 5Milvus v2.6.17 release notes — GitHub
- 6Qdrant v1.18.1 release notes — GitHub
- 7Weaviate v1.35.21 — GitHub
- 8Weaviate v1.36.15 — GitHub
- 9MySQL 9.7.0 PGO Benchmark Analysis — Percona Blog
- 10Running TidesDB as a MySQL 9.7 storage engine — Percona Blog
- 11Not All Open Source Is Equal: Choosing a PostgreSQL Operator for Kubernetes in 2026 — Percona Blog
- 12Migrate from Crunchy Data to Percona PostgreSQL Operator: Standby Cluster Method — Percona Blog
- 13Manually Migrate Hash Slots in a Valkey/Redis Cluster — Percona Blog
- 14CVE-2026-8053: "We don't use time-series" is not a mitigation — Percona Blog
- 15PostgreSQL backup tool gets some backup of its own after sole maintainer sounds alarm — The Register
- 16Introducing ExtendDB: An open source DynamoDB-compatible adapter with pluggable storage backends — AWS Database Blog
- 17Show HN: Prisma Next — data contracts, migration graphs, agent DX
このコンテンツについて、さらに観点や背景を補足しましょう。