
HF Breakout Models, May 18 – June 1: On-Device MoE, Physical AI, and Cohere Goes Apache
Eleven HF models with explosive download growth across a two-week window (May 18 – June 1): poolside's Laguna XS.2 leads at 218k monthly downloads with Apache 2.0 agentic coding at 3B active parameters; LFM2.5 and MiniCPM5 push the on-device MoE frontier; Cohere releases its first fully Apache 2.0 model (Command A+); NVIDIA launches the open Cosmos 3 physical AI model family; Microsoft drops MIT-licensed T2I models Lens and Lens-Turbo. All entries include license status and builder-specific deployment guidance.

This edition covers two weeks of model activity on Hugging Face — the May 25 run was skipped due to a platform outage, so models from May 18 through June 1 are all in scope here. The net result: more cumulative download signal per entry than usual, and a cleaner read of which models actually have legs vs. which just spiked on launch day.
The dominant theme across both weeks is efficient deployment over raw scale. The top-downloaded models are either on-device MoE architectures pushing the limits of 1.5B–11B active parameters, or research bets on entirely novel compute patterns (diffusion decoding, dual-timescale recurrence). NVIDIA made the biggest single splash — not with another LLM, but by open-sourcing its physical AI foundation model family. Eleven models worth reading about; most worth evaluating this week.
LLMs
Laguna XS.2 — 218k downloads, Apache 2.0, agentic coding
poolside's Laguna XS.2 is the most-downloaded new model in this window by a wide margin: 217,996 monthly downloads as of June 1, less than a week after the model card was last updated. 1
The architecture is a 33B total / 3B active Mixture-of-Experts (MoE), with 256 experts plus one shared expert. The attention design splits 30 of 40 layers into Sliding Window Attention (512-token window) and keeps 10 as global attention, at a 3:1 ratio — a pattern that cuts KV cache memory significantly at long-context. FP8 KV quantization is built in. Context window: 262,144 tokens. 1
Benchmark results: SWE-bench Verified 69.9%, SWE-bench Multilingual 57.7%, SWE-bench Pro 46.3%, Terminal-Bench 2.0 35.7%. These put it in serious competition with models 5–10× its active parameter count on agentic coding tasks. 1
The speculative decoding story is unusually clean here: poolside ships a companion DFlash drafter that triples accepted decode length, and the model natively interleaves reasoning tokens between tool calls. Ollama support is first-class; vLLM, Transformers, and TRT-LLM are all covered. A 36 GB Mac can run it.
- License: Apache 2.0 — commercial use fully permitted
- Active params: 3B (33B total MoE)
- Context: 262k tokens
- Deployment: Ollama (local, 36 GB RAM), vLLM, TRT-LLM, Transformers
- Builder angle: best-in-class open agentic coding model at the 3B-active weight class; drop it into any SWE-agent or code-review pipeline. The DFlash drafter makes sustained agentic loops (long multi-step tasks) meaningfully faster than a dense model at the same active count.
HRM-Text-1B — 150k downloads, Apache 2.0, architecture research bet
Sapient Intelligence's HRM-Text-1B is the most architecturally novel model in this window. The Hierarchical Reasoning Model (HRM) uses two Transformer modules stacked in a dual-timescale recurrence loop: a slow High-level module (H) and a fast Low-level module (L), cycling at H×L = 2×3. The key claim is "effectively unbounded compute depth" without scaling parameter count — more inference-time compute is added by cycling the stack more times, not by adding weights. 2
Download signal: 149,543 monthly downloads, 438 likes — substantial traction for a base model checkpoint with no chat interface. It was trained on 40B tokens of primarily English text; no code data. The model card is explicit that this is a pre-alignment checkpoint — it is not a chat assistant and cannot be used for dialogue out of the box. Getting useful output requires fine-tuning (SFT/RL) on top of the base. The
token_type_ids PrefixLM attention mask is also non-standard and needs explicit handling. The arXiv paper is 2605.20613 ("HRM-Text: Efficient Pretraining Beyond Scaling"). 2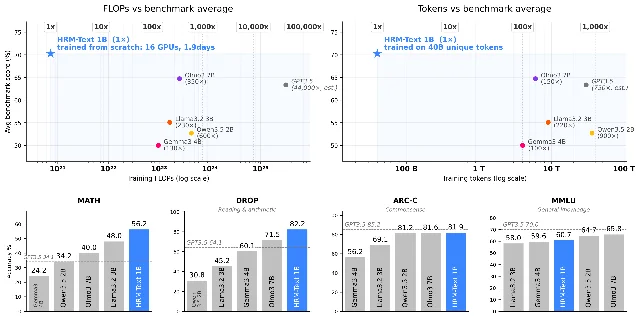
- License: Apache 2.0
- Params: 1B (16-layer per H/L stack, hidden dim 1536, 12 attention heads)
- Training: 40B tokens, English-primary, no code
- Builder angle: this is a research base, not a drop-in. Worth watching if you're building fine-tuned vertical models in the 1B range — the architecture's compute-depth scaling could unlock cheaper inference-time reasoning than chain-of-thought prompting. Don't expect it to replace an instruction-tuned model without your own fine-tuning pipeline.
LFM2.5-8B-A1B — ~119k combined downloads, Apache 2.0, on-device MoE
Liquid AI's LFM2.5-8B-A1B is a hybrid architecture: 18 dual-gated LIV convolution layers plus 6 GQA attention layers, 8.3B total / 1.5B active parameters, 128k context, trained on 38 trillion tokens. 3
Downloads across variants: main model 37,893, GGUF 55,194, unsloth GGUF 25,559 — ~119k combined. The performance claims are specific: AA-Omniscience Index improved from -78.42 in LFM2 to -24.70 in LFM2.5 (+53.62 points — the index runs from -100 to +100); IFEval from 79.44 to 91.84. CPU inference speed is stated as fastest in class at this size, with GPU throughput at 18,500 output tokens/second on H100 under high concurrency. 3
Supported deployment surfaces: llama.cpp, MLX (Apple Silicon), vLLM, SGLang, LM Studio. Nine languages: English, Arabic, Chinese, French, German, Japanese, Korean, Portuguese, Spanish.
- License: Apache 2.0 — commercial use fully permitted
- Active params: 1.5B (8.3B total)
- Context: 128k tokens
- Best for: agentic workflows, tool use, structured outputs, multilingual assistants
- Not suited for: heavy coding tasks, knowledge-intensive Q&A without retrieval
- Builder angle: the CPU-first performance profile is the practical differentiator. If you're deploying an assistant on user devices (mobile, laptop, edge server with no GPU), this is currently the best open Apache 2.0 option for instruction following at this weight class. Recommended inference settings: temperature 0.2, top_k 80, repetition_penalty 1.05.
MiniCPM5-1B — ~77k combined downloads, Apache 2.0, best 1B class for tool use
OpenBMB's MiniCPM5-1B pushes the 1B frontier with a post-training recipe that goes well beyond standard SFT. The training chain: 200B tokens of deep-thinking SFT → 200B tokens of mixed-thinking SFT → RL teacher training → on-policy distillation (OPD). The RL+OPD stage delivers an average 16-point gain on math, code, and instruction following benchmarks, and reduces over-long responses by 29 percentage points. 4
Downloads: main model 45,698, GGUF 24,065 — ~77k combined, 678 likes. Architecture is a standard LlamaForCausalLM, 24 layers, 16Q/2KV GQA heads, 131,072-token context. The same checkpoint handles both thinking and non-thinking modes; no separate variants needed. Hardware support via FlagOS covers 9 chip families (NVIDIA, Hygon, Metax, Iluvatar, Ascend, and others). 4
- License: Apache 2.0
- Params: 1B dense, 131k context
- Standout tasks: agentic tool use, code generation, difficult reasoning at 1B scale
- Builder angle: if you're constrained to 1B parameters — edge deployment, on-device assistants, high-throughput inference at low cost — MiniCPM5-1B is the current open-source benchmark leader in this tier for tool calling. The hybrid Think/No Think mode means you can add a reasoning trace cheaply without a model swap.
Command A+ — 19k downloads, Apache 2.0, Cohere's licensing milestone
CohereLabs released Command A+ on May 20: a 25B active / 218B total sparse MoE, 128 experts with 8 active per token plus one shared expert, 3:1 alternating sliding-window and global attention (RoPE), 128k input / 64k output context, 48 languages, vision input. 5
The model's technical specs are competitive, but the headline is the license: this is Cohere's first fully Apache 2.0 model. Every previous Cohere open release carried commercial restrictions. The quantization story is also notable — BF16, FP8, and W4A4 variants are available, with W4A4 fitting on a single B200 or two H100s. Native Grounding Citations (inline source attribution) are built in at the model level, not added via prompting. 5
Deployment: vLLM >= 0.21.0; also accessible through the Cohere Dashboard and API.
- License: Apache 2.0 — commercial use fully permitted
- Active params: 25B (218B total MoE)
- Context: 128k in / 64k out
- Languages: 48
- Builder angle: the enterprise agent use case is the clear target — multilingual, grounded citations, vision. The 19k monthly downloads likely underrepresent real usage given the API path. If you've avoided Cohere models because of license restrictions, that blocker is gone now.
Multimodal
Step-3.7-Flash — ~76k combined downloads, Apache 2.0, agent-first VLM
StepFun's Step-3.7-Flash is a 198B MoE (about 11B active parameters per token) vision-language model with a 1.8B visual encoder and a 256k-token context window. It dropped on May 31 and accumulated ~76k combined downloads across the main model, GGUF, and NVFP4 variants within hours. 6
Benchmark highlights: ClawEval-1.1 67.1 (first place — ClawEval tests multi-step agentic tasks including search, code execution, and planning), SWE-bench PRO 56.3 (second place), SimpleVQA (Search) 79.2 (first), V* Python 95.3. Three selectable reasoning depths (low/medium/high) let you trade latency for quality at inference time; max throughput is 400 tokens/second. API pricing: $0.20/M input tokens (cache miss), $1.15/M output tokens. 6
Local deployment requires at least 128 GB of unified memory, so this is a server/cloud model for most builders. Supported runtimes: vLLM, SGLang, Transformers, llama.cpp.
- License: Apache 2.0
- Active params: ~11B (198B total MoE), 256k context
- Builder angle: the search + perception + reasoning combination is what makes Step-3.7-Flash interesting for agents that need to process web content alongside images. The ClawEval first-place score covers exactly that pattern. Self-hosting is 128 GB RAM minimum; for most indie builders, OpenRouter or the StepFun API is the practical route.
Nemotron-Labs-Diffusion-14B — NVIDIA Open Model License, tri-mode decoder
NVIDIA's Nemotron-Labs-Diffusion-14B introduces a language model that can switch between three decoding modes at inference time — autoregressive (AR), parallel diffusion, and self-speculation — by changing attention patterns, without separate model weights. 7
The practical implications: in diffusion mode, the model decodes multiple tokens in parallel, shifting generation from memory-bound to compute-bound — which is why the 8B variant reaches 850 tok/sec on GB200 and 112 tok/sec on DGX Spark with w4a16. Self-speculation mode outpaces Qwen3-8B-Eagle3 by 2.2× on SGLang. The 14B variant has 7,225 monthly downloads; the 8B sibling has ~47k. 7
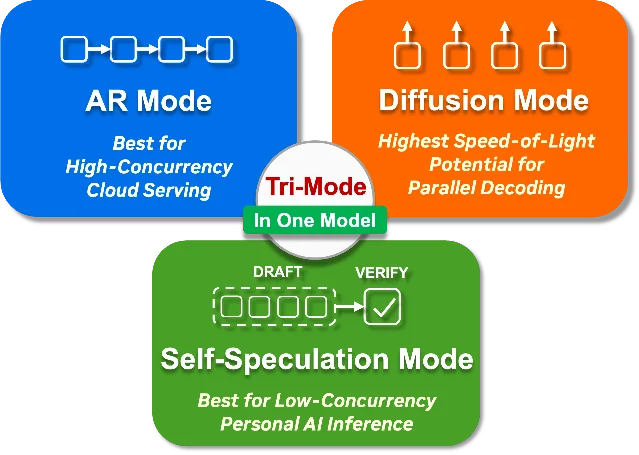
The family includes base, instruct, and vision-language variants across 3B/8B/14B sizes.
- License: NVIDIA Open Model License (commercial use allowed for most cases — read the terms; restrictions apply to competing GPU products)
- Builder angle: diffusion decoding is not yet mainstream in production inference stacks, but the throughput numbers are specific and verifiable. If you're running inference at scale on NVIDIA hardware and can tolerate a non-Apache license, the diffusion mode throughput numbers — 850 tok/sec on GB200, 2.2× self-speculation advantage on SGLang — are hard to match with comparable-sized dense models. The LoRA-augmented drafter is a free upgrade for acceptance length.
Image and video generation
NVIDIA Cosmos 3 Super — OpenMDW1.1, physical AI image and video
NVIDIA released the Cosmos 3 Super family on May 31: Cosmos3-Super-Text2Image (65B) and Cosmos3-Super-Image2Video (65B), plus a Cosmos3-Nano (16B) optimized for RTX PRO 6000 workstations. The architecture uses Mixture-of-Transformers (MoT): one autoregressive transformer handles reasoning and understanding, one diffusion transformer handles continuous-modality generation — meaning text, images, video, audio, and action data can all flow through a single model. 8 9
Training data: 1.3B data points across 393 datasets — 767M images, 348M video clips, 139M audio segments, 8M action sequences. The Image2Video model generates 189 frames at 24fps by default. Six synthetic data generation datasets for physical AI scenarios were released alongside the models. 8
The day-one Reddit discussion on r/StableDiffusion focused mostly on the 65B hardware requirements — realistically a multi-GPU or cloud workload for most builders.
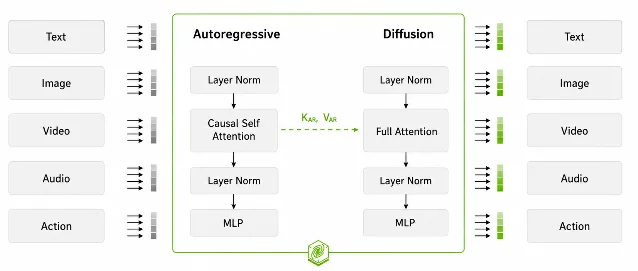
- License: OpenMDW1.1 — commercial and non-commercial use both explicitly permitted
- Models: Cosmos3-Super-T2I (65B), Cosmos3-Super-I2V (65B), Cosmos3-Nano (16B)
- Integrations: diffusers (Cosmos3OmniPipeline), vLLM-Omni, PyTorch
- Builder angle: the Nano variant is the accessible entry point — sized for a single high-end workstation GPU. The broader Cosmos 3 bet is on physical AI (robotics, simulation, embodied agents), where the combination of visual generation and action data matters. For standard image/video generation workflows without robotics intent, the 65B models are overkill.
Microsoft Lens and Lens-Turbo — MIT license, T2I from scratch
Microsoft dropped two text-to-image models on May 20: Lens (3.8B) and Lens-Turbo (4-step distilled). Both use a 48-block MMDiT (Multimodal Diffusion Transformer) architecture with a FLUX.2 semantic VAE and multi-layer text features from GPT-OSS. Training dataset: Lens-800M — 800M image-text pairs with GPT-4.1 long-form descriptions. Supported resolutions up to 1440×1440, with aspect ratios from 1:2 to 2:1. 10 11
Lens uses 20-step sampling with CFG 5.0; Lens-Turbo runs 4 steps at CFG 1.0 — faster for low-latency pipelines. Downloads after 11 days: Lens 2,306, Lens-Turbo 2,020. Early community variants already include 4 fine-tunes and 3 quantized builds. The arXiv paper is 2605.21573. 10
- License: MIT — fully open, commercial use with no restrictions
- Resolution: up to 1440×1440, multi-aspect-ratio
- Builder angle: Lens-Turbo's 4-step inference makes it competitive on latency with SDXL Turbo-class models while operating at higher resolution. With an MIT license and Microsoft research pedigree, it's a credible base for fine-tuning brand or product image generators. The download numbers are still early — community quality benchmarks are sparse — but the architecture and training setup look solid for a new foundation model.
Audio
MOSS-TTS-v1.5 — 18.6k downloads in 6 days, 31 languages, explicit pause control
OpenMOSS-Team's MOSS-TTS-v1.5 landed on May 25 and pulled 18,564 monthly downloads in under a week. The upgrade from v1.0 expands language support from 20 to 31 — new additions include Cantonese, Dutch, Finnish, Hindi, Malay, Romanian, Swahili, Tagalog, Thai, and Vietnamese — and adds an explicit pause syntax: insert
[pause 3.2s] directly into the input text to control breath timing. 128B parameters. The v1.5 update also improves voice clone stability (less variance across repeated generations of the same reference clip), punctuation-following prosody, and long-reference short-text cloning quality. Three HF Spaces demos are available. The research paper is arXiv:2603.18090. 12
- License: check HF repo (arXiv paper and demo available under OpenMOSS terms — verify before commercial deployment)
- Params: 8B
- Languages: 31 (see model card for full list)
- Builder angle: the
[pause X.Ys]control is the practical differentiator for long-form content — podcasts, audiobooks, voice UI. Most open TTS systems either force you to split at punctuation or add silence in post. Voice clone quality at 8B scale with 31 languages is stronger than any sub-1B open TTS in this space.
Google MedASR — 14.6k downloads in 6 days, 4.6% WER on radiology dictation
Google released MedASR through its Health AI Developer Foundations program on May 25: a 105M-parameter Conformer-architecture ASR model trained on approximately 5,000 hours of de-identified physician dictation across radiology, internal medicine, family medicine, and related specialties. 13
The accuracy gap versus general-purpose ASR is large. On the RAD-DICT radiology dictation benchmark with a 6-gram language model added: MedASR WER 4.6% vs. Whisper Large v3 at 25.3% and Gemini 2.5 Pro at 10.0%. It ranked first across all tested medical datasets in the model card. 13
Limitations are explicit in the model card: English only, primarily US accents, high-quality microphone audio. The model is accessed via HuggingFace with agreement to the Health AI Developer Foundations terms of use (requires login). Transformers 5.0.0+ pipeline API. After six days: 14,631 downloads, 4 fine-tunes, 4 quantizations, 19 Spaces. 13
- License: Health AI Developer Foundations terms (requires agreement on HF — not Apache/MIT; read terms before deploying in a product)
- Params: 105M Conformer
- Languages: English only
- Builder angle: if you're building a medical documentation product — clinical note generation from dictation, radiology report drafting, patient intake transcription — MedASR at 4.6% WER is the best open English medical ASR available. The fine-tuning footprint (105M) is small enough to adapt on a single GPU with a few hundred hours of your own domain data.
On the radar for next issue
Three models are close but not yet open-weight on HuggingFace:
- NVIDIA Nemotron-3-Ultra — announced, expected June 4 release
- MiniMax M3 — community signals around June 10
- JetBrains Mellum2-12B-A2.5B (Thinking + Instruct variants) — dropped on June 1 with under 100 downloads; needs another week to assess adoption
Qwen 3.7 remains API-only. 14 No open weights on HF as of publication; Alibaba's Max-series models have not been open-sourced historically.
The week's pattern in one line
The architectures getting traction are all built around the same constraint: minimize active parameters at inference time, maximize context and capability. Laguna XS.2 at 3B active, LFM2.5 at 1.5B, MiniCPM5 at 1B dense, Command A+ at 25B of 218B — the download distribution rewards models that run on hardware most builders actually have. The outliers (Cosmos 3, Step-3.7-Flash) are either specialized for robotics/physical AI or require cloud-scale serving. The architectural experiments — HRM's dual-timescale recurrence, Nemotron-Diffusion's tri-mode decoding — are research bets worth watching but not deploying against production traffic yet.
Cover image: AI-generated illustration
参考ソース
- 1poolside/Laguna-XS.2 · Hugging Face
- 2sapientinc/HRM-Text-1B · Hugging Face
- 3LiquidAI/LFM2.5-8B-A1B · Hugging Face
- 4openbmb/MiniCPM5-1B · Hugging Face
- 5CohereLabs/command-a-plus-05-2026-bf16 · Hugging Face
- 6stepfun-ai/Step-3.7-Flash · Hugging Face
- 7nvidia/Nemotron-Labs-Diffusion-14B · Hugging Face
- 8nvidia/Cosmos3-Super-Image2Video · Hugging Face
- 9NVIDIA: Welcome NVIDIA Cosmos 3 · HuggingFace Blog
- 10microsoft/Lens · Hugging Face
- 11microsoft/Lens-Turbo · Hugging Face
- 12OpenMOSS-Team/MOSS-TTS-v1.5 · Hugging Face
- 13google/medasr · Hugging Face
- 14r/LocalLLaMA: Open Models – May 2026
このコンテンツについて、さらに観点や背景を補足しましょう。